Cybozu Frontend Monthly #9

イベント概要
サイボウズフロントエンドマンスリー は、サイボウズ社内で行っているフロントエンド情報共有会「フロントエンドウィークリー」の公開版です。
その月に気になったフロントエンドの情報を、サイボウズのフロントエンドエキスパートチームのメンバーが共有していきます。
このイベントのハッシュタグは #サイボウズフロントエンドマンスリー です。
※フロントエンドウィークリーとは
毎週火曜の 17:00 〜 18:00
で社内向けに行っているフロントエンドの気になる記事を紹介する会です。2016年3月15日から行われています。
ハッシュタグ
#サイボウズフロントエンドウィークリー
で実況しています。
zennのpublicationにてウィークリーのまとめも投稿していますので、ぜひこちらもご覧ください。 https://zenn.dev/p/cybozu_frontend
開催日
2021年03月30日
イベントページ
https://cybozu.connpass.com/event/208515/
配信URL
https://www.youtube.com/watch?v=AZy7IvmMRjE
メンバー







ゲスト


コンテンツ
Compat2021: Eliminating five top compatibility pain points on the web
- 共有者: sakito
Compat2021という取り組みの紹介記事になります。 同時にマイクロソフト、IgaliaからもCompat2021についての各社の取り組みについて記事が公開されています。
WebDNAなどを通して行われてきた調査で浮き彫りになった開発者が感じている問題について「ブラウザーの互換性」が多くあがっており、その問題について改善していくという内容になっています。 特にCSS関連でCSS Flexbox, CSS Grid, CSS position: sticky, CSS aspect-ratio property, CSS transformsが各ブラウザで微妙に挙動が異なることによる辛さが多く挙げられているので、ここを2021年は改善していくとのことです。
記事では具体的にどのような挙動の差があるのかもまとまっています。
メーリングリストやweb-platform-tests dashboard - Compat 2021 Dashboardで情報を追いかけることができるのと、今後も継続的にこの問題について情報があがってくるようです。
Chromium以外にもGeckoやWebKitも改善されないと意味がないような気がしますが、WebKitについてはIgaliaが取り組みについて触れているのでIgaliaがWebKitに協力していき、ほかのベンダーが共同でブラウザの改善に取り組むのかもしれません。
CSSの微妙な違いについてはかなり直面するケースでもあり、確認も大変なので嬉しい取り組みだと思います。
テキストに隠し情報を埋め込むnpmモジュールを公開しました
- 共有者: nakajmg
電子透かしを入れることなどを目的とした、表示されない文字を使ってテキストにデータを埋め込む話。
テキストをコピーしてね👆のテキストをコピーして https://zero-width-watermark-web.vercel.app/ で XTRACT MODEにしてコピペしてExtractを実行すると…。
👐
実装としてはテキストをUint8Arrayに変換して0と1をゼロ幅文字(0x200cと0x200b)に変換して埋め込んでいます。
この手法は数年前に話題になったことがありました。
ゼロ幅文字にエンコードした隠し情報で、文書をリークしたメンバーを特定
How MDN’s site-search works - Mozilla Hacks - the Web developer blog
- 共有者: zaki___yama
リニューアルしたMDNのサイト内検索のしくみの話。
2021年2月時点で、MDNには
- 英語のドキュメントが 11,619 ページ
- 翻訳されたドキュメントが約 40,000 ページ
- 英語だけで 530 万語
存在するそうです。 ビルド時にこれらのデータを全文検索データベースに突っ込んでインデックスする、ということをやっています。 データベースとして現在採用しているのは Elasticsearch です。
サイト全体のアーキテクチャ
以下の図がわかりやすい。
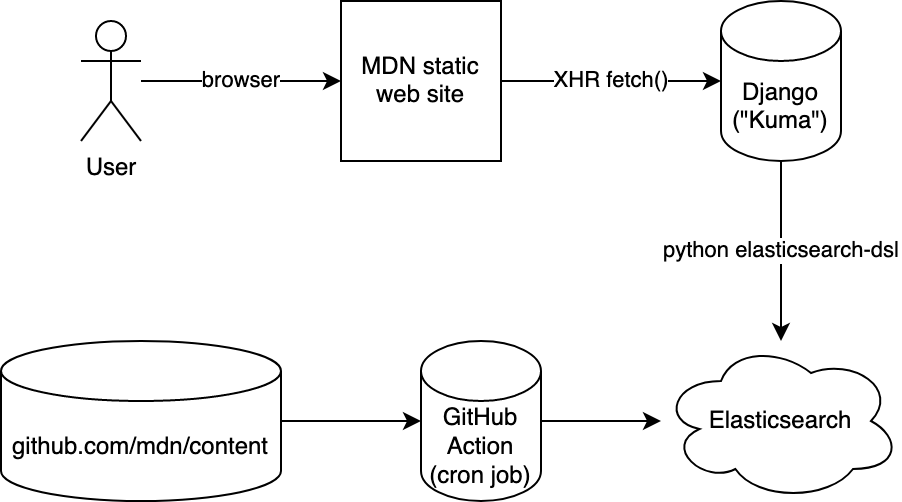
サイトのコンテンツを Elasticsearch に突っ込む、という処理を GitHub Actions で定期実行しています。 (24h おき) また、検索時はフロントエンドからの fetch() リクエストを一旦 Django で構築したバックエンドが受け取り、クエリのバリデーションや整形をした後 Elasticsearch に送っています。
インデックス化までの流れ
- ビルド時、コンテンツから index.html と一緒に index.json というデータを生成する。これは以下のようなデータ
{
"doc": {
"title": "DOCUMENT TITLE",
"summary": "DOCUMENT SUMMARY",
"body": [
{
"type": "prose",
"value": {
"id": "introduction",
"title": "INTRODUCTION",
"content": "<p>FIRST BLOCK OF TEXTS</p>"
}
},
...
],
"popularity": 0.12345,
...
}- Python のスクリプトで、index.json のHTMLからタグを取り除いた純粋なコンテンツを得る
- これは
<p>Some <em>cool</em> text.</p>->Some cool text.のような単純な処理だけではなく、<div class="hidden">や<div class="notecard warning">なども取り除く必要がある
- これは
- Elasticsearch に送る
- …という処理を 24 時間おきに GitHub Actions で実行
- production build 用の GitHub Action はおそらく prod-build.yml
- 削除されたページのインデックスなどを考慮し、Elasticsearch 側は毎回インデックスを全削除 -> 再作成している
検索
- フロントエンドからは
fetch()でGET /api/v1/search?q=foo&locale=frのようなエンドポイントを叩く - バックエンドでは Django のアプリがこのクエリをバリデーションし Elasticsearch 用のクエリに変換して検索
- elasticsearch-dsl というライブラリを使っている
- 検索結果のソート:popularity という数値を定義し、popularity と matchness を組み合わせてソートしてる
- popularity: Google Analytics の PV 数(定期的にダウンロードしてる)を 0 ~ 1 の値に正規化したもの
Error Cause in JavaScript - DEV Community
- 共有者: pirosikick
Errorのコンストラクタの第2引数に他のエラーを渡すことができるプロポーザルについて。知らぬ間にもうStage 3になっていた。 下流で起きたエラーを上流に流していく過程で、エラーメッセージを連結したり、独自のエラーを作ったりせずに、 このような言語で公式の方法ができると色々と使いまわしがよさそう。 (Golangではエラーをラップして返すのはおなじみで、結構便利。)
const cause = new Error('…');
const err = new Error('…', { cause });
console.log(err.cause === cause); // true同じようなことをやってくれるverrorというのがあるが、
たぶんUniversalじゃないし、そこまでメジャーでは無い気がする。
この提案をベースに、Golangのerrors.Asみたいなのを作ると便利そう。
// errがtype型のErrorをcauseに持っている場合に返す
// 適当に書いたので間違いあるかも!
function errorAs<
T extends { new (...args: any[]): InstanceType<T> }
>(err: Error, type: T): InstanceType<T> | null {
while(err) {
if (err instanceof type) {
return err;
}
err = err.cause;
}
return null;
}
const cause = new MyError('...');
const err = new Error('...', { cause });
const e = errorAs(err, MyError);
if (e) {
// eはMyErrorとして扱える
}Post-Spectre Web Development
- 共有者: shisama
Spectre以降のWeb開発について脅威モデルと対策の実践例が解説されているドキュメントがW3CのWorking Draft(草案)として公開されました。元々GoogleのMike West氏が書いた文書でしたがW3C organizationに移りました。
Spectreのようなサイドチャネル攻撃はハードウェアの脆弱性に起因するものなので、Same-Origin Policyでは防ぐことができません。機密情報が攻撃者によって操作可能なプロセスの中にあった場合、サイドチャネル攻撃によって情報の推測がされることが実証されています。JavaScriptを使ったSpectreのPoCも公開されました。
プロセスレベルでサイトを分離するChromiumのSite IsolationやFirefoxのProject Fissionがあり、これらはデフォルトで有効となっているため、eTLD+1が異なるURLのサイトはプロセスが別となります。
ただ、すべてのブラウザがこれを実装するのは難しいため、Opt-inで対策可能なHTTPヘッダーを用意しています。
この文書ではそれらのHTTPヘッダーの設定方法が詳しく紹介されています。
『Google Developers Japan: サイドチャネル攻撃への対策』でも紹介されている内容+補足は以下の通り。
これはW3CのドキュメントのTL;DRにも書かれている内容です。
- 受信したヘッダーを調べ、一方で Origin ヘッダー、もう一方で Sec-Fetch- で始まる各ヘッダーに注目し、リクエストに応答するべきかどうかを判断します。
- (補足)
Sec-Fetch-*からはじまるFetch Metadataはリクエスト時にChromeによって自動で付与されます。Fetch Metadataにはどこからきたどのようなリクエストかの情報が含まれています。
- (補足)
- 攻撃者がリソースをサブリソースとして読み込む機能を制限します。これをするには、Cross-Origin Resource Policy として same-origin を設定します(必要な場合のみ、same-site または cross-origin にします)。
- (補足)配信されるリソースに設定します。CDNなどで配信しているようなCross-Originで使われるリソースには値にcross-originを設定する必要があります。
- 攻撃者がリソースをドキュメントとしてフレームに含めることができるかを制限します。これをするには、X-Frame-Options: SAMEORIGIN を使ってフレーム化保護にオプトインするか、さらに細かい制御が可能な CSP の frame-ancestors ディレクティブを使います。たとえば、
frame-ancestors 'self' https://trusted.embedderとします。- (補足)iframeなどに埋め込めることができるページをSame-Originに制限したり、指定したOriginのみに制限できます。
- 攻撃者がアプリケーションのウィンドウを参照する機能を制限します。これをするには、Cross-Origin Opener Policy を設定します。制限が強い same-origin 値をデフォルトとし、必要な場合のみ same-origin-allow-popups または unsafe-none にするのが最適です。
- (補足)
Cross-Origin-Opener-Policy: same-originが設定されているページから新しいウィンドウで開かれたCross-Originなページからはwindow.openerの値がnullになります。
- (補足)
- MIME-type confusion 攻撃を防ぎ、Cross-Origin Read Blocking(クロスオリジン読み込みブロック)などの消極的防御の確実性を高めます。これをするには、正しい Content-Type ヘッダーを設定し、X-Content-Type-Options: nosniff となっていることをグローバルで確認します。
- (補足)
<img>や<script>を使って機密情報が含まれたHTMLやJSONを取得することを利用したサイドチャネル攻撃がある。たとえば<img src="https://example.com/secret.json">のようなリクエストを攻撃者のサイトから行われたとき、見た目上は画像のパースに失敗して表示されないだけだが、攻撃者のコードのあるプロセス内のメモリに展開される。メモリに展開されたデータはサイドチャネル攻撃により推測可能となる。CORBはこのようなメモリへの展開を防ぐことができる機能です。
- (補足)
W3Cのドキュメントにはこれらの内容について実際のHTTPヘッダーの設定例をケースごとに実例を交えて解説しています。
また、『2.2.1. Fully-Isolated Documents』のNoteにも書かれていますが、Chrome 91からSharedArrayBufferを使うためにはCross-Origin Isolateな状態でないと利用できなくなります。
これらの機能を使うためには次のようにCross-Originなページからのアクセスを防ぐ設定が必要です。
Cross-Origin-Embedder-Policy: require-corp
Cross-Origin-Opener-Policy: same-originPerformance APIなどもSite IsolationやこれらのHTTPヘッダーの設定が必要です。サイドチャネル攻撃の可能性があるAPIはCross-Origin Isolatedでないと使えないようになるかもしれません。 どのように設定すればいいか迷ったときはこのドキュメントを参考に設定すると良さそうです。
SharedArrayBuffer
- 共有者: koh110
Chrome 91からSharedArrayBufferの利用するためにヘッダーを返さなければならなくなりました。
https://developer.chrome.com/blog/enabling-shared-array-buffer/
- 使っているつもりはなかったが検出された
- Next.jsが入れているっぽい
- https://github.com/vercel/next.js/issues/21708
- 依存して検出されてしまっているが影響はない
- Reactの依存だった
- 最終的にSharedArrayBufferへの依存が削除された
- https://github.com/facebook/react/releases/tag/v17.0.2
- https://github.com/facebook/react/pull/20840
- セキュリティなどの重大なissueではないためv16へのバックポートはない
もとをたどるとScheduler(React内部パッケージ)のプロファイリング機能で使われている
Scheduler
元々はreact-schedulerというパッケージ
react-scheduler -> schedule -> scheduler
https://github.com/facebook/react/pull/13543
https://github.com/facebook/react/pull/13683
https://github.com/facebook/react/tree/master/packages/scheduler
中身を読んでみるとイベントキューのようなもの
https://github.com/facebook/react/blob/master/packages/scheduler/src/forks/SchedulerDOM.js
renameが繰り返されるうちに説明文が消えたっぽい。
requestAnimationFrameやrequestIdleCallbackより細かい優先度をつけて実行するというモチベーション。
https://github.com/facebook/react/blob/8a1e3962ab189b99b1593d8431feabcb4a21211b/packages/react-scheduler/src/ReactScheduler.js#L12-L23
Node.js + 古いIE環境を判定するために typeof setImmediate をみてるのがちょっと面白い。
https://github.com/facebook/react/blob/master/packages/scheduler/src/forks/SchedulerDOM.js#L555-L556
Profiler
https://reactjs.org/docs/profiler.html https://gist.github.com/bvaughn/8de925562903afd2e7a12554adcdda16
Schedulerのプロファイリングには2つのアプローチが採用されている
https://github.com/facebook/react/pull/16145
https://github.com/facebook/react/pull/16542
- sample base
- workerからSchedulerの現在の状態を読み取る
- workerとSchedulerのデータを共有するためにSharedArrayBufferが使われている
- event base
- Workerが初期化される前にプロファイリングするためのもの
プロファイリングはdevelopmentビルドでしか有効にされていないため、SharedArrayBufferの問題はproduction環境では起きないはず。
production環境でSharedArrayBufferの警告が出ている場合developmentビルドのままリリースしている可能性やProfilerをonにしている可能性があるので、アップデートできない環境やフレームワークで依存している場合は気にしてみるとよいかも。
https://gist.github.com/bvaughn/25e6233aeb1b4f0cdb8d8366e54a3977
TC39 2020 March(03/09, 03/10)
- 共有者: @__sosukesuzuki
数が多いのでいくつか興味深いかつあんまりメジャーではなさそうなものをあえて紹介。
Class Static Initialization Blocks
Class Foo {
static {
this.foo = "foo";
}
}現在条件付きのStage-3。
前回の論点は2つあった。
一つはクラスごとに複数のStatic Blocksを許可するかどうかという点だった。結論としては、クラスは任意の数のStatic Blocksを含むことができるようになった。
もう一つは、Static Blocks内でのnew.target挙動についてだった。結論としては、メソッドと同じようにundefinedを返す必要があるということになった。
この提案の中ではStatic Blocksに対するデコレータの扱いはサポートしていない。最終的にデコレータによるサポートが必要なのであれば、それはデコレータの提案の一部もしくは別のものとして議論する。
SpiderMonkeyやV8ではすでに実装が始まっている。
Records and Tuples update
現在Stage-2。
2019年10月のStage-1のときのスライドでの議論に戻るが、TuplesやRecordsのために書いたコードは配列やオブジェクトに対しても動作するべきである。最近になって、配列のメソッドとTuplesのメソッドを照らし合わせていたところ、配列を操作するpopped, pushed, reversed, shifted, spliced, unshifted, with などのメソッドが配列には存在しないことがわかった。
もしこれらのメソッドがArray.prototypeに存在すれば、この例のように配列を無駄にコピーする必要がなくなる。
- const a2 = [...a1].reverse();
+ const a2 = a1.reversed();
- const a3 = [...a2].sort();
+ const a3 = a2.sorted();Tuplesのみならず配列にとっても有用なものである可能性が高い。
なので、これらのメソッドをArray.prototypeやTuple.prototypeに追加するというのを Records & Tuples とは異なる新しいプロポーザルとして管理することが決まった。
Async Do update towards stage 2
現在Stage-1。
前回からの変更点が2つある。
1つめは、doのブロックの中でbreak,continue,returnが使えるようになる。アンケートの結果そのような挙動に賛成する人が多かったため仕様に修正が加えられた。
2つ目は、doのブロックの最後の文として、elseなしのifは認めないようになった。ifの直前の値を返すべきか、undefinedを返すべきか不明瞭だからである。
// x is 3? or undefined?
const x = do {
3
if (false) {
2
}
}タイトルはtowards stage 2だが、まだ固まっておらず今後設計を洗練させるという結論になった。
Promise.anySettled
これは厳密にはプロポーザルではない。
Promise.raceは統一性のためにPromise.anySettledという名前であるべきではないかという議論。
| name | description | status |
|---|---|---|
Promise.allSettled | 短絡しない | ES2020 |
Promise.all | 入力のどれかが失敗したら短絡する | ES2015 |
Promise.race | 入力のどれかが完了したら短絡する | ES2015 |
Promise.any | 入力のどれかが成功したら短絡する | ES2021 |
このような表にしてみるとわかりやすくなる。
新しいPromise.anySettledを導入、既存のPromise.raceをその別名にして、全く同一の関数オブジェクトを指すようにするという提案。
結論としては、この提案はコンセンサスが得られなかった。
議論であげられている懸念が3つあった。
一つは、一度導入された関数の名前を変更するというのは互換性の観点からよくないということ。具体的にいえばAMPはPromise.raceの名前に依存したAPIを提供しているらしい。
もうひとつは、プログラムは書かれることよりも読まれることが多いことを考えると、名前の異なる挙動が全く同じ関数を導入するというのは読み手に対して不親切であるという点。書くのみならPromise.anySettledのみを覚えておけば問題ないが、読む場合には両方の関数とその関係を把握しておく必要が出てしまう。
最後の懸案は、単純にraceとanySettledという2つの言葉の意味には違いがあるという点。ほとんどのPromiseに対する標準のオペレーションは”success confluence”(「計算の結果は、内部の処理の順番に影響されない」)という性質があり、入力のPromiseがすべて成功した場合には成功した順番に影響されない計算結果になるようになっている。Promise.raceはこの性質に反する操作であり、それを強調するためにあえてこの名前が使われているらしい。
Announcing the Deno Company
- 共有者: b4h0_c4t
Deno社が声明を発表していた。
要約すると、
- Deno(以下、ランタイムを指す)はブラウザAPIに準拠したモダンなプログラミングシステムである
- 490万ドルのseed capitalを得たことでフルタイムの開発スタッフを確保できたため、タイムリーに開発が進むようになる。
- Denoの展開は直接的なマネタイズが目的ではない
「490万ドルの資金調達に成功した」あたりが話題性の高い内容なのかなという感じでした。
CSS aspect-ratio の各ブラウザ実装が揃いつつある
- 共有者: narirow
CSSで比率を計算して要素のサイズを表現できるaspect-ratio、今月多くのブラウザで実装が進みました。各ブラウザの動向をまとめると以下のようなステータスです。
- GoogleChrome: 88でリリース済み (2020年10月)
- Chrome90でaspect-ratioのCSSアニメーションに対応 (参考)
- Firefox: 88でリリース予定 (2021年4月)
- Safari: TechnologyPreview117から徐々に対応、テスト中
aspect-ratioは、特に画像や映像のあとから読み込みされたときに発生するガタツキ(CLS)が以前より問題視されて、intrinsicsizeなどのプロパティを経て、数年間議論が進んでいました。 先立って、ブラウザの内部ではaspect-ratioを使用したスタイルをあてて、ガタツキが発生しないように調整が行われていたりします。
上記にも上がっていますが、GoogleはCompat2021というプロジェクトを立ち上げ、Webの互換性の問題に取り組んでいます。aspect-ratioプロパティはその中でも優先度の高いものとして取り上げられています。
プロダクションで使えるようになるのも、あと少しですね。
PWAでもスクリーンショットが登録できるように
- 共有者: narirow
manifest.jsonがAndroidChromeで強化されます。
screenshotsと、descriptionのフィールドを入力しておくと、アプリストアのような立地なインストール画面を立ち上げることができるようになります。
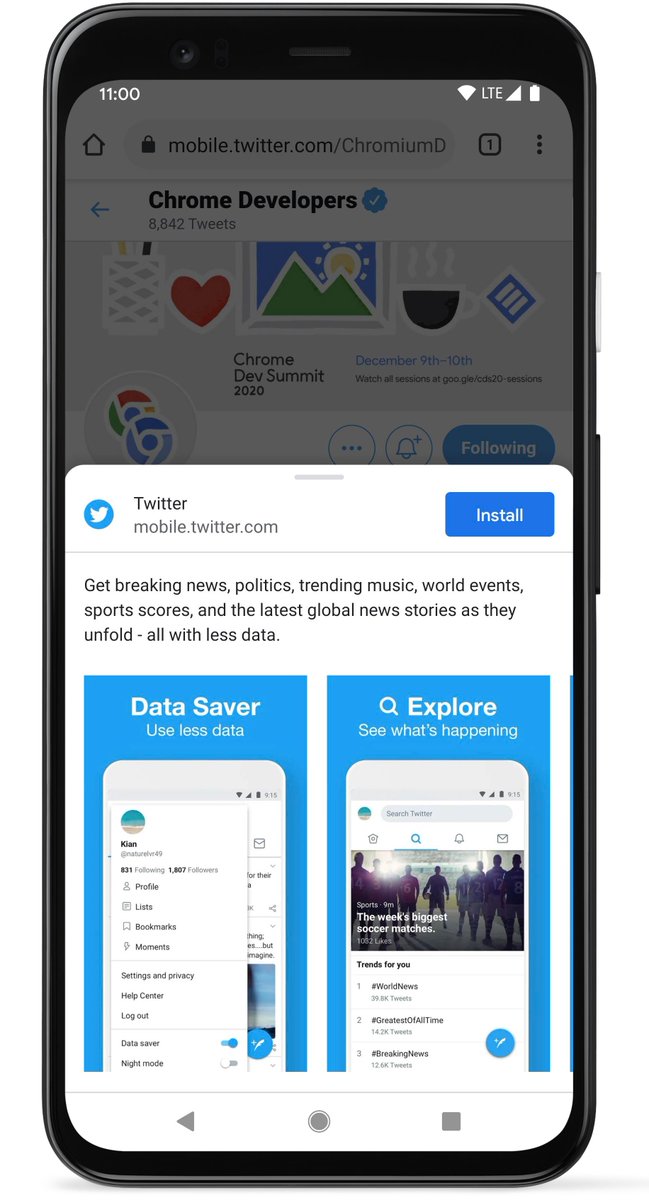
(ChromiumDevツイートから転載: https://twitter.com/ChromiumDev/status/1376472636058927104)
LaytoutShiftを効率的にdebugする (web.dev) + Chrome90でCLS算出方法がアップデート
- 共有者: narirow
web.devでCoreWebVitalsの一つである、レイアウトシフトのデバッグ方法について詳細に記載れています。
レイアウトシフトに換算される要素は 直近でユーザーの入力に基づいて変更されていない要素で、これは PerformanceObserverで検出されるデータのうち、hadRecentInputがfalseになっている要素が該当します。
以下のようなスクリプトをChromeのデバッグツールのsnippetを追加したり、bookmarkletとして用意しておくとConsole画面で便利にデバッグ出来ます。
new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntries()) {
if (!entry.hadRecentInput) {
cls += entry.value;
debugger;
console.log('Current CLS value:', cls, entry);
}
}
}).observe({type: 'layout-shift', buffered: true});(web.devより転載)
CLSの検出方法は、実は日々アップデートされています。この更新はChromeSpeedのページから見ることが出来ます。Chrome89から、opacity:0が当てられているような目に見えない要素がCLSから換算されなくなり、Chrome90でもこの方向性が強化され、空白のテキストやtransformなどの不具合も修正されます。
CoreWebVitalsの対応を行っている方は、Chrome90がリリースされた後、変化が起きないかSearchConsoleから確認してみると良いでしょう。